Insights
Teaching a Machine to Think Like a Clinician

Inside Century Health's approach to extracting reliable, structured insights from the messy, multimodal world of clinical data, and how we use reinforcement learning to continuously improve our models.
Physician's notes are notoriously messy. Typed observations, handwritten notes, scanned lab reports, imaging studies, and coded diagnoses all come together to form a fragmented record of a patient's health over years. It can take a clinician hours to piece together this data for just one patient; that's where the Century Health Abstraction & Retrieval Model (CHARM) comes in.
At Century Health we extract structured, actionable insights from exactly this kind of data. The work we do, called clinical data abstraction, sits at the intersection of medicine and machine learning. The way we've built our system reflects lessons learned across thousands of real patient records, countless model iterations, and deep collaboration between our engineers and our clinical team.
This post walks through how we think about the problem, how our system is structured, and why we believe the combination of human expertise and reinforcement learning is the right approach for healthcare AI.
Clinical Data is Complicated
When most people think about medical records, they imagine clean spreadsheets: a row per patient, columns for every metric. The reality is far more complex.
A single patient's record might include physician-authored narrative notes, scanned documents from referring providers, structured fields from an electronic health record, and imaging metadata, all for a single clinical visit. Now imagine multiple visits per year across a lifetime of treatment. That's a lot of data.
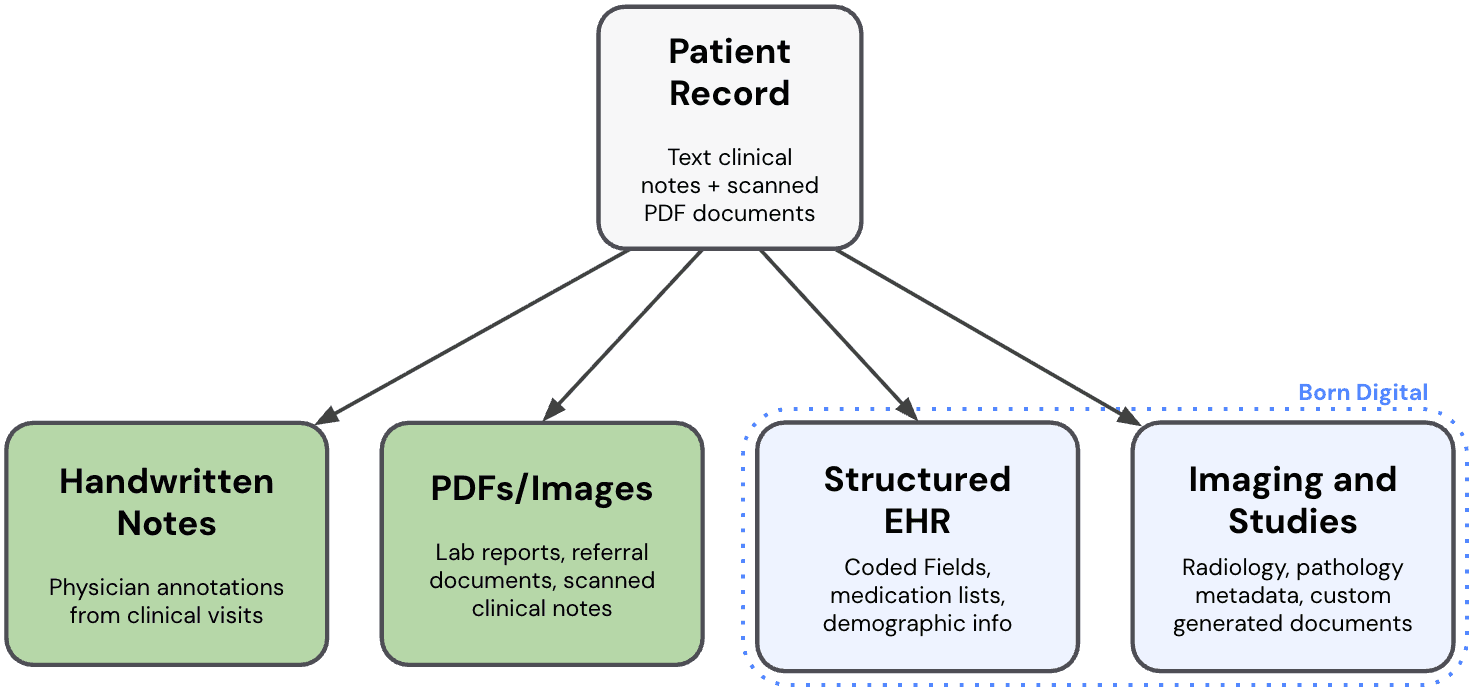
Figure 1: A single patient record branching into its component types: handwritten note, images, structured EHR data, and other custom documents.
Extracting a single variable from that record, for example, whether a patient received a particular type of treatment, or what the physician's assessment of disease severity was, requires reading across formats, handling ambiguity, and making judgment calls that experienced clinicians spend years learning to make.
The goal is not to replace clinical judgment, but rather to scale it: reliably, at speed, and across millions of records that no human could ever review alone.
Our Foundation
Modern AI models already possess a remarkable base of medical and clinical knowledge. They can parse complex sentences, understand the relationship between symptoms and diagnoses, and reason about medical context in surprisingly sophisticated ways.
Unfortunately, "surprisingly sophisticated" isn't good enough for clinical use. A model that gets the right answer 85% of the time may be excellent by general AI benchmarks, but in healthcare, that means 15 out of every 100 abstractions may be wrong, and for decisions made downstream, those errors can have profound impacts. Sometimes there is more than one way to interpret diagnoses; sometimes a model needs to know when not to answer.
Our starting point is a foundation model paired with carefully designed clinical instructions: context and examples that tell the model what to look for, how to handle edge cases, and what kind of output is expected. Think of it as an onboarding document: something you'd hand to a brilliant new hire who knows medicine but doesn't yet know your specific task.
The result is the CHARM system. We build a separate model for each clinical dataset, and in some cases for each individual variable we're abstracting. This is because the judgment required to extract, for example, a diagnosis, is different from that required to extract a treatment date or a severity score.
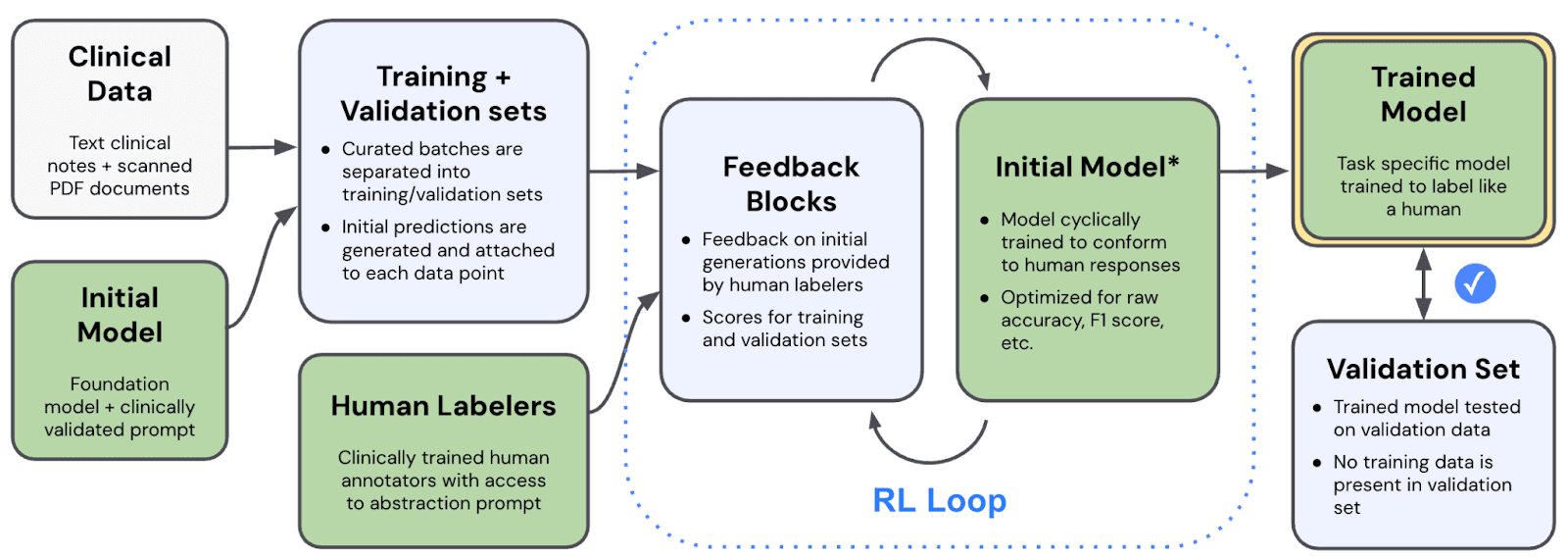
Figure 2: An example of how one variable is abstracted from unstructured multimodal clinical data
Raw Records to Labeled Truth
Before we can improve CHARM, we need to know what "correct" looks like. This requires building a high-quality labeled dataset: a collection of real cases where expert humans have reviewed the clinical data and provided ground-truth answers.
Our pipeline begins by running an initial model on a curated batch of patient records. The model produces predictions, structured outputs for each case, and those predictions, along with the underlying clinical data, are queued for human review. Our clinically trained annotators then examine each case, score the model's output, and write feedback explaining any errors.
The output of this process is a structured dataset of cases, each paired with human-verified ground truth and annotator commentary. This becomes the foundation for everything that follows.
Reinforcement Learning with Human Feedback
Once we have a labeled dataset, we enter the RL loop: a reinforcement learning cycle that continuously improves CHARM's performance by teaching it to match human clinical judgment.
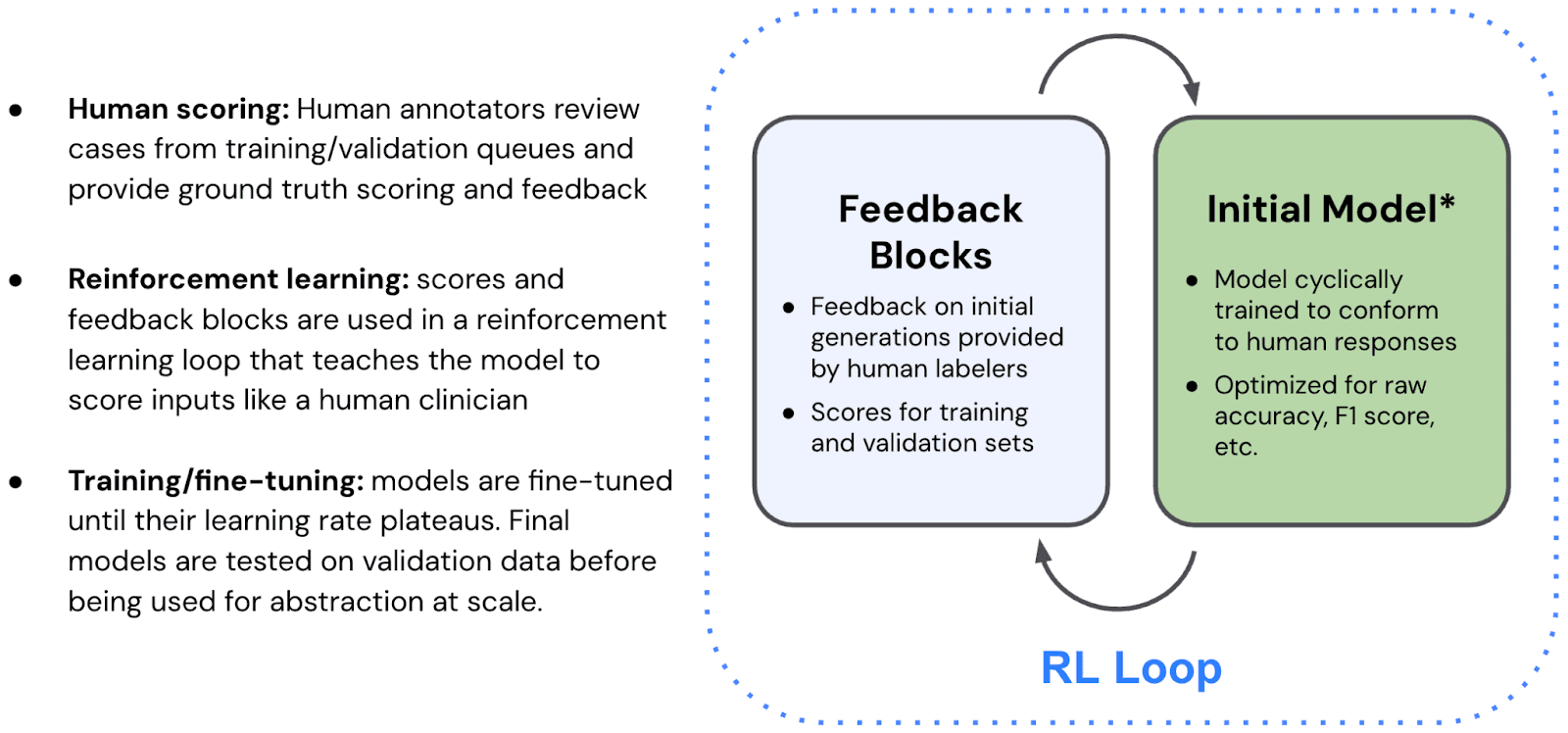
Figure 3: Aligning our model to human annotators
The process works like this: we identify the cases where CHARM got it wrong. We analyze those failures. What patterns do they share? What kinds of errors is the model making systematically? Is it being too aggressive in certain diagnoses? Too conservative? Missing key signals in the clinical narrative?
That analysis becomes structured feedback, which drives candidate improvements to the model. We then test those improvements against our labeled dataset, measuring which version performs best, not just on average — but on the specific failure cases we're trying to address.
CHARM is refined in a continuous cycle: generate predictions, collect expert feedback, improve the model, test it, and repeat. We run separate training and validation sets to ensure CHARM isn't just overfitting to cases it has already seen. A version of CHARM is only deployed once it demonstrates strong performance on data it has never encountered before.
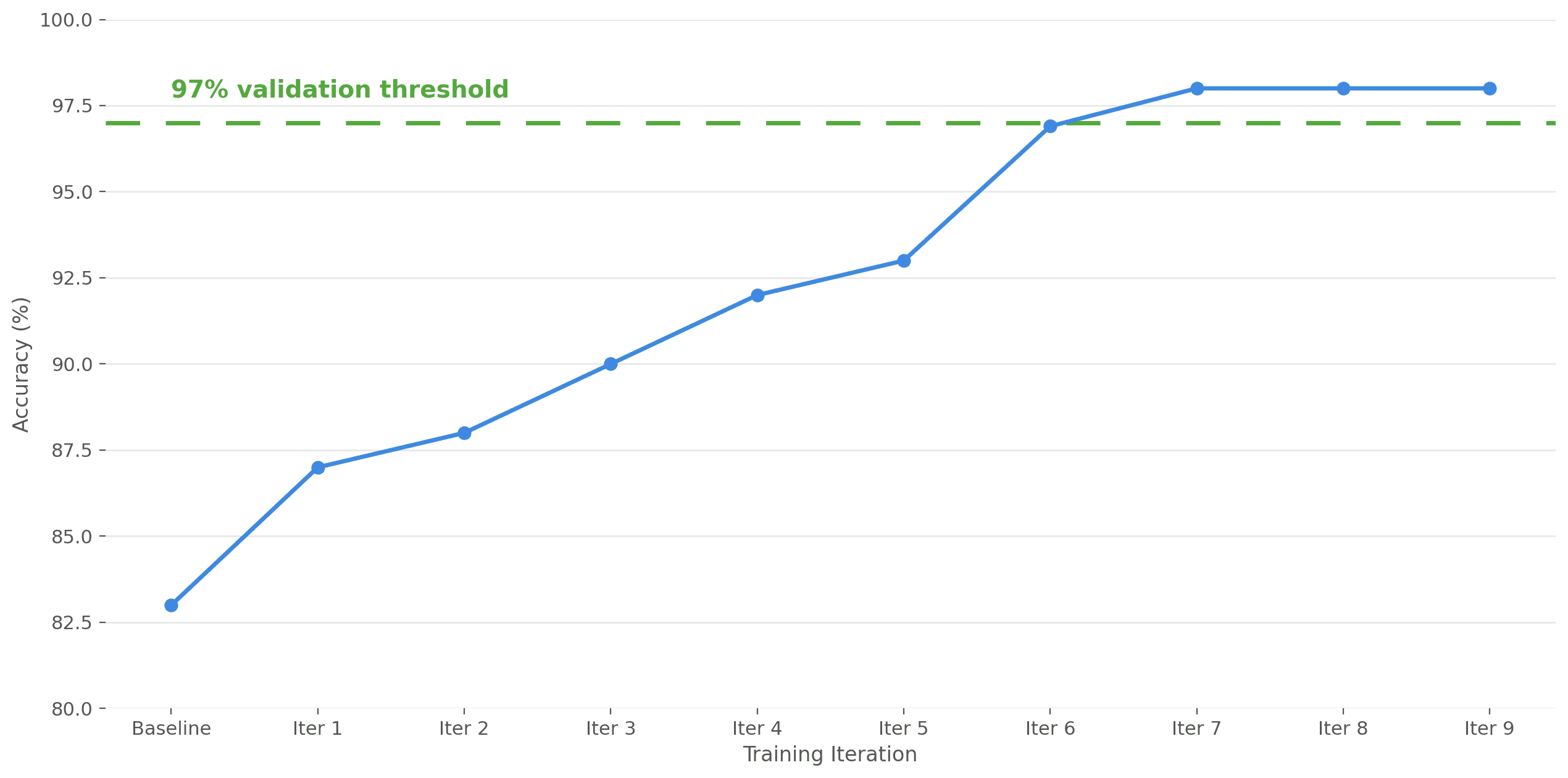
Figure 4: CHARM training accuracy on real clinical data from a MASH dataset. Accuracy improvements from human feedback.
The Role of Human Expertise
It would be easy to look at our pipeline and see the AI as the main character. It isn't. CHARM is the engine, but our clinically trained annotators are holding the wheel.
Everything in our system ultimately traces back to human judgment. The ground truth labels that train CHARM come from clinicians. The feedback that drives our reinforcement learning loop comes from clinicians. The benchmarks that determine whether CHARM is ready for deployment are graded against clinician-provided answers.
This is by design. Healthcare AI that drifts from clinical grounding, however sophisticated its architecture, cannot be trusted. Our annotators are the teachers, and CHARM is a student trying to replicate their expertise.
Where We're Headed
The cases that remain hardest for CHARM are the ones that are hardest for humans too: ambiguous clinical narratives, conflicting information across sources, rare diagnoses with limited training examples, and judgments that require synthesizing years of patient history at once.
Our roadmap is focused on expanding the range of clinical variables CHARM can reliably abstract, improving our handling of complex multimodal inputs, and making our feedback loop faster so that newly identified failure modes get addressed instantly.
If this problem sounds interesting to you, or if you have clinical data you think CHARM could help with, we'd love to talk.


